×
![]()
mining: Instance-to-Instance Comparison Results
| Type: | Instance |
| Submitter: | Kelly Eurek |
| Description: | Unspecified mining application. Mark Zuckerberg suggests the following tightening of one class of constraints: The variables in this problem (except for the last one, x348921, which is fixed to 1 and does not appear in any constraint) are arranged in groups of 20, and there are three classes of precedence constraints (or more accurately, implication constraints): 1) For each variable index i=-,348920, if i mod 20 > 0 then there is a constraint x_i 2) If i mod 20 = and i>20 then there is a constraint x_i = x21 >= x41 >=-) 3) and for all other i there is a constraint x_i Graphically, we can represent the variables as a table with height twenty and width 348920 / 20, with indices 1,-,20 going down the left-most column, then 21,-,40 going down the next column to the right, etc. There is then a precedence constraint (1) from each variable in a column to the one below it, a precedence constraint (2) from the topmost entry in each column to its neighbor on the left, and an "OR" precedence constraint (3) from each entry that isn't on top of a column, requiring that if it has value 1 then either the one above it or the one to its left must have value 1 as well. But in fact this OR precedence (3) can be replaced with a simple precedence constraint from each variable to the one at its left. To see this note that in any column, the first type of precedence constraint will require that a feasible solution must be a contiguous sequence of 1's from some point in the column until the bottom. Consider column c > 1. The topmost 1 in this column, by precedence constraints (3) (or if the topmost is at the top of the column, then by precedence constraints (2)) implies that the variable to its left (in column c-1) is also 1, which implies that the contiguous sequence of 1's in column c-1 must be at least as high as the sequence in column c. Thus for every 1 in column c, the entry to its left in column c-1 must also be 1. |
| MIPLIB Entry |
Parent Instance (mining)
All other instances below were be compared against this "query" instance.  |
 |
 |
 |
 |
 |
|
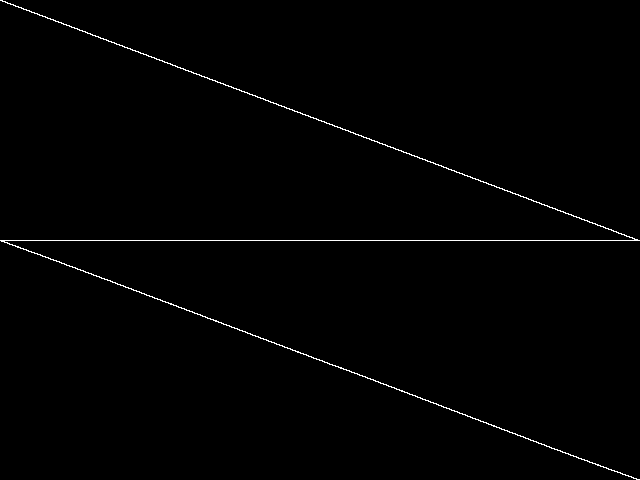
Raw
This is the CCM image before the decomposition procedure has been applied.
|
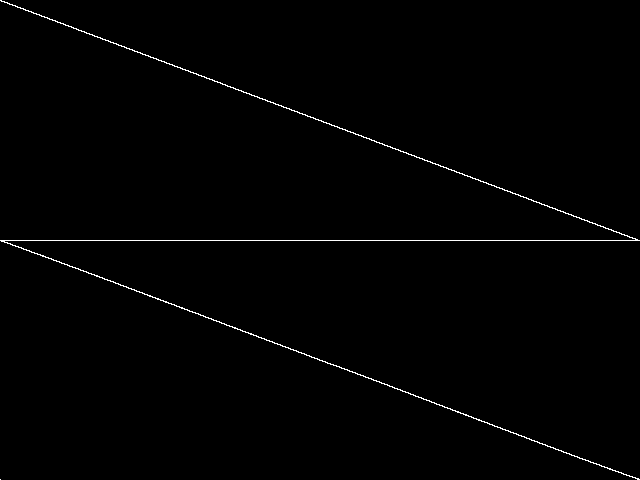
Decomposed
This is the CCM image after a decomposition procedure has been applied. This is the image used by the MIC's image-based comparisons for this query instance.
|
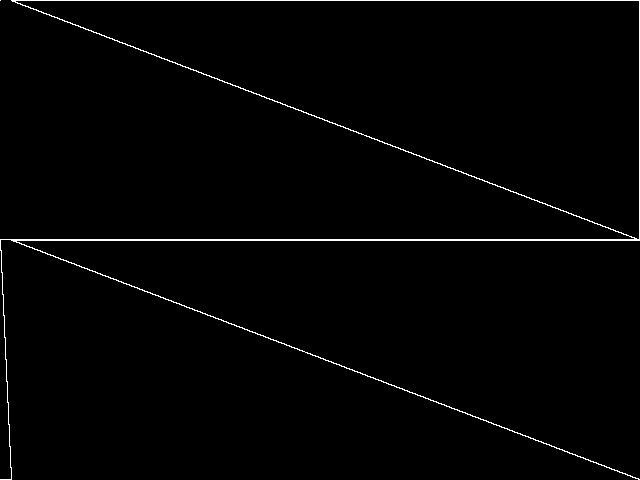
Composite of MIC Top 5
Composite of the five decomposed CCM images from the MIC Top 5.
|
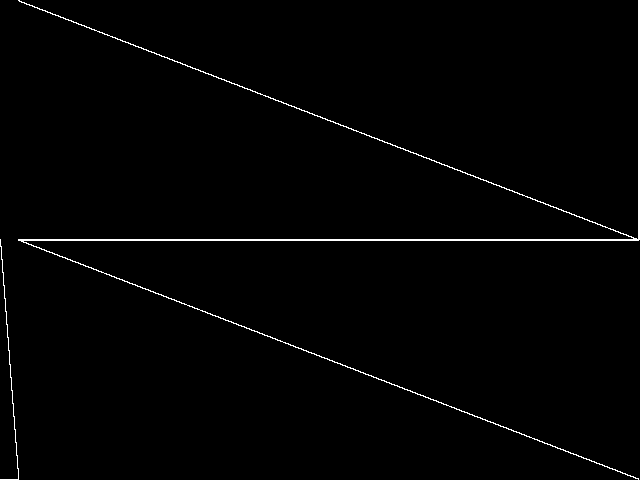
Composite of MIPLIB Top 5
Composite of the five decomposed CCM images from the MIPLIB Top 5.
|
Model Group Composite Image
Composite of the decomposed CCM images for every instance in the same model group as this query.
|
MIC Top 5 Instances
These are the 5 decomposed CCM images that are most similar to decomposed CCM image for the the query instance, according to the ISS metric. |
Decomposed
These decomposed images were created by GCG.
|
 |
 |
 |
 |
 |
| Name | neos-4532248-waihi [MIPLIB] | neos-4391920-timok [MIPLIB] | neos-4359986-taipa [MIPLIB] | neos-633273 [MIPLIB] | neos-829552 [MIPLIB] | |
|
Rank / ISS
The image-based structural similarity (ISS) metric measures the Euclidean distance between the image-based feature vectors for the query instance and all other instances. A smaller ISS value indicates greater similarity.
|
1 / 0.377 | 2 / 0.420 | 3 / 0.466 | 4 / 0.508 | 5 / 0.556 | |
|
Raw
These images represent the CCM images in their raw forms (before any decomposition was applied) for the MIC top 5.
|
 |
 |
 |
 |
 |
MIPLIB Top 5 Instances
These are the 5 instances that are most closely related to the query instance, according to the instance statistic-based similarity measure employed by MIPLIB 2017 |
Decomposed
These decomposed images were created by GCG.
|
 |
 |
 |
 |
 |
| Name | rmine21 [MIPLIB] | rmine15 [MIPLIB] | rmine13 [MIPLIB] | opm2-z12-s8 [MIPLIB] | rmine21** [MIPLIB] | |
|
Rank / ISS
The image-based structural similarity (ISS) metric measures the Euclidean distance between the image-based feature vectors for the query instance and all model groups. A smaller ISS value indicates greater similarity.
|
362 / 1.538 | 428 / 1.583 | 519 / 1.639 | 918 / 2.670 | N.A.** / N.A.** | |
|
Raw
These images represent the CCM images in their raw forms (before any decomposition was applied) for the MIPLIB top 5.
|
 |
 |
 |
 |
 |
Instance Summary
The table below contains summary information for mining, the five most similar instances to mining according to the MIC, and the five most similar instances to mining according to MIPLIB 2017.
| INSTANCE | SUBMITTER | DESCRIPTION | ISS | RANK | |
|---|---|---|---|---|---|
| Parent Instance | mining [MIPLIB] | Kelly Eurek | Unspecified mining application. Mark Zuckerberg suggests the following tightening of one class of constraints: The variables in this problem (except for the last one, x348921, which is fixed to 1 and does not appear in any constraint) are arranged in groups of 20, and there are three classes of precedence constraints (or more accurately, implication constraints): 1) For each variable index i=-,348920, if i mod 20 > 0 then there is a constraint x_i 2) If i mod 20 = and i>20 then there is a constraint x_i = x21 >= x41 >=-) 3) and for all other i there is a constraint x_i Graphically, we can represent the variables as a table with height twenty and width 348920 / 20, with indices 1,-,20 going down the left-most column, then 21,-,40 going down the next column to the right, etc. There is then a precedence constraint (1) from each variable in a column to the one below it, a precedence constraint (2) from the topmost entry in each column to its neighbor on the left, and an "OR" precedence constraint (3) from each entry that isn't on top of a column, requiring that if it has value 1 then either the one above it or the one to its left must have value 1 as well. But in fact this OR precedence (3) can be replaced with a simple precedence constraint from each variable to the one at its left. To see this note that in any column, the first type of precedence constraint will require that a feasible solution must be a contiguous sequence of 1's from some point in the column until the bottom. Consider column c > 1. The topmost 1 in this column, by precedence constraints (3) (or if the topmost is at the top of the column, then by precedence constraints (2)) implies that the variable to its left (in column c-1) is also 1, which implies that the contiguous sequence of 1's in column c-1 must be at least as high as the sequence in column c. Thus for every 1 in column c, the entry to its left in column c-1 must also be 1. | 0.000000 | - |
| MIC Top 5 | neos-4532248-waihi [MIPLIB] | Jeff Linderoth | (None provided) | 0.377050 | 1 |
| neos-4391920-timok [MIPLIB] | Jeff Linderoth | (None provided) | 0.419749 | 2 | |
| neos-4359986-taipa [MIPLIB] | Jeff Linderoth | (None provided) | 0.465685 | 3 | |
| neos-633273 [MIPLIB] | NEOS Server Submission | Collection of anonymous submissions to the NEOS Server for Optimization | 0.508107 | 4 | |
| neos-829552 [MIPLIB] | NEOS Server Submission | Imported from the MIPLIB2010 submissions. | 0.555775 | 5 | |
| MIPLIB Top 5 | rmine21 [MIPLIB] | Daniel Espinoza | Instance coming from open pit mining over a cube considering multiple time periods and two knapsack constraints per period | 1.538287 | 362 |
| rmine15 [MIPLIB] | Daniel Espinoza | Set of instances comming from open pit minning over a cube and several time periods and two knapsack constraints per period | 1.583352 | 428 | |
| rmine13 [MIPLIB] | Daniel Espinoza | Set of instances comming from open pit minning over a cube and several time periods and two knapsack constraints per period | 1.638718 | 519 | |
| opm2-z12-s8 [MIPLIB] | Daniel Espinoza | Problems coming from precedence constrained knapsacks arising in mining applications. These are one-period problems with integer data but large root LP GAP | 2.670430 | 918 | |
| rmine21** [MIPLIB] | Daniel Espinoza | Instance coming from open pit mining over a cube considering multiple time periods and two knapsack constraints per period | N.A.** | N.A.** |
mining: Instance-to-Model Comparison Results
| Model Group Assignment from MIPLIB: | no model group assignment |
| Assigned Model Group Rank/ISS in the MIC: | N.A. / N.A. |
MIC Top 5 Model Groups
These are the 5 model group composite (MGC) images that are most similar to the decomposed CCM image for the query instance, according to the ISS metric. |
These are model group composite (MGC) images for the MIC top 5 model groups.
|
 |
 |
 |
 |
 |
| Name | proteindesign | neos-pseudoapplication-95 | 8div | scp | markshare | |
|
Rank / ISS
The image-based structural similarity (ISS) metric measures the Euclidean distance between the image-based feature vectors for the query instance and all other instances. A smaller ISS value indicates greater similarity.
|
1 / 1.405 | 2 / 1.429 | 3 / 1.520 | 4 / 1.696 | 5 / 1.705 |
Model Group Summary
The table below contains summary information for the five most similar model groups to mining according to the MIC.
| MODEL GROUP | SUBMITTER | DESCRIPTION | ISS | RANK | |
|---|---|---|---|---|---|
| MIC Top 5 | proteindesign | Gleb Belov | Linearized Constraint Programming models of the MiniZinc Challenges 2012-2016. I should be able to produce versions with indicator constraints supported by Gurobi and CPLEX, however don't know if you can use them and if there is a standard format. These MPS were produced by Gurobi 7.0.2 using the MiniZinc develop branch on eb536656062ca13325a96b5d0881742c7d0e3c38 | 1.404573 | 1 |
| neos-pseudoapplication-95 | NEOS Server Submission | Imported from the MIPLIB2010 submissions. | 1.428714 | 2 | |
| 8div | Sascha Kurz | Projective binary 8-divisible linear block codes A linear block code is called 8-divisible if the weights of its codewords are divisible by 8. It is called projective if there are no duplicate columns in the generator matrix. The possible lengths of 8-divisible linear block codes have been classified except for length n=59, where it is undecided whether such a linear code exists. The possible dimensions satisfy \\(10 \\le k \\le 20\\). Model 8div_n59_kXX contains the corresponding feasibility problem. Projective binary 8-divisible linear block codes occur as hole configurations of so-called partial solid spreads in finite geometry. Binary 4-divisible linear block codes have applications in physics. | 1.519735 | 3 | |
| scp | Shunji Umetani | This is a random test model generator for SCP using the scheme of the following paper, namely the column cost c[j] are integer randomly generated from [1,100]; every column covers at least one row; and every row is covered by at least two columns. see reference: E. Balas and A. Ho, Set covering algorithms using cutting planes, heuristics, and subgradient optimization: A computational study, Mathematical Programming, 12 (1980), 37-60. We have newly generated Classes I-N with the following parameter values, where each class has five models. We have also generated reduced models by a standard pricing method in the following paper: S. Umetani and M. Yagiura, Relaxation heuristics for the set covering problem, Journal of the Operations Research Society of Japan, 50 (2007), 350-375. You can obtain the model generator program from the following web site. https://sites.google.com/site/shunjiumetani/benchmark | 1.695589 | 4 | |
| markshare | G. Cornuéjols, M. Dawande | Market sharing problem | 1.705439 | 5 |
